Table of Contents
Analyzing PG&E data with VisiData
At the PG&E website, you can download a CSV table of your energy usage. Click “Energy Usage Details” and then the “Green Button” at their site to download your data.

PG&E CSVs come with 5 rows of metadata followed by Type, Date, Start Time, End Time, Usage, Units, Cost, Notes columns. Delete the five rows of metadata in a text editor, or use tail to remove them like so (or with tail -n +6 for older tail):
tail +6 pge_electric_interval_data.csv | vd -f csv -
Then prepare your PG&E data like so:
Set Column Types, Widths, Names, Importance
| Key | Meaning |
|---|---|
| - | Hide columns TYPE, END TIME, UNITS and NOTES |
| = | Create a new column for weekday. Enter “DATE.weekday()” |
| = | Create a new column for weekday name. Enter “DATE.strftime('%A')” |
| ^ | Rename “START TIME” to one word since column names should be one word for Python expressions. |
| C | Go to column mode and… |
| t | Select the DATE and START TIME columns |
| & | Make a new column that merges them |
| - | (Optionally delete some columns' rows from column mode to really delete columns from the sheet.) |
| q, - | Quit the Column mode, hide (sets their width to 0) DATE and START TIME columns |
| O | Go to options mode and… |
| e | Set disp_date_fmt to %Y-%m-%d %H:%M (or do it in column mode's fmtstr for the one column.) |
| q | Quit options mode. |
| @!, %, $ | Set DATE_START_TIME to date format and important, USAGE to float, COST to currency |
| = | Add a column, enter COST/USAGE, (Make it float with %) |
| ^ | Rename COST/USAGE to kWh rate |
| H,V and _ | Move and resize the columns. |
You should end up with a sheet with usable data. Note that @ means “date format”, # means “integer”, % means “float” and $ means “currency”. Also note that we haven't set aggregator types yet. We'll use those for frequency tables.
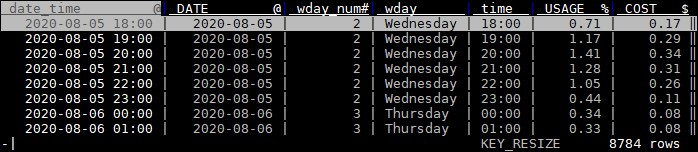
View average usage by hour of day
| Key | Meaning |
|---|---|
| - | Hide all columns, leaving only time, USAGE, and COST |
| + | On USAGE and COST, set aggregator type to… say, avg for average. |
| F | On the time column, tap F to get a frequency table. |
| [ | The frequency table is sorted on the new aggregations, on time column, use [ to sort by time again. |
| - | Remove the new count column. |
| C, e, “%H:%M”, q, @! | Go to column mode, set time column format to %H:%M, exit column mode, set time to date format. |
| g. | Display a graph with all visible columns. |
| -, + | Zoom in and out of the graph. |
| q, q | Quit the graph, quit the frequency sheet |
| C, t, ge, 8 | Column mode, toggle date_time, DATE, wday_num, wday, edit width to 8, to see these columns again. |
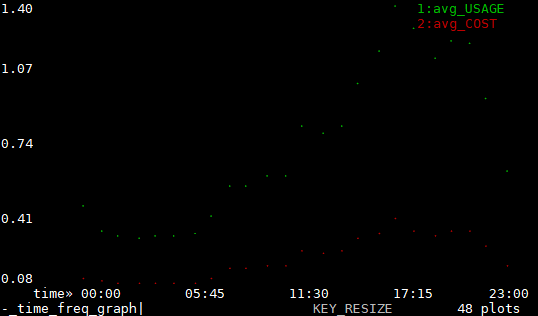
View average usage by day of week
| Key | Meaning |
|---|---|
| - | Hide all columns, leaving only wday_num, time, USAGE, and COST |
| C, t, & | Column mode, toggle wday_num, time, make a new column that joins them. |
| = | With TIME as string format, make a new row as int(int(TIME[:2])/4)*4 |
Select Rows to Analyze
Directly selecting ranges of rows:
| Key | Meaning |
|---|---|
| s,t,u | Select/toggle/unselect current row. |
| , | Select all rows matching value of current cell |
| gs,gt,gu | … all rows |
| zs,zt,zu | … from top to cursor |
| gzs,gzt,gzu | … from cursor to bottom (Or… zs,gt, one less thing to remember) |
| “ | Open duplicate sheet with only selected rows. |
Select based on a pattern:
| Key | Meaning |
|---|---|
| | | On DATE_START_TIME column, select by regex, like ”-11-“ for November |
| z| | Select rows matching Python expr “DATE_START_TIME [-3:] == '-07'” |
| ” | To open a new sheet with just those selected rows. |
Visualize Data
| Key | Meaning |
|---|---|
| . or g. | Select columns to graph them. Notice rate changes. Notice times of high use. |
| +, - | Navigate with hjkl, zoom in and out (more) |
Further Resources
I have another tutorial at VisiData that merges/joins three CSV tables.